Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?
-
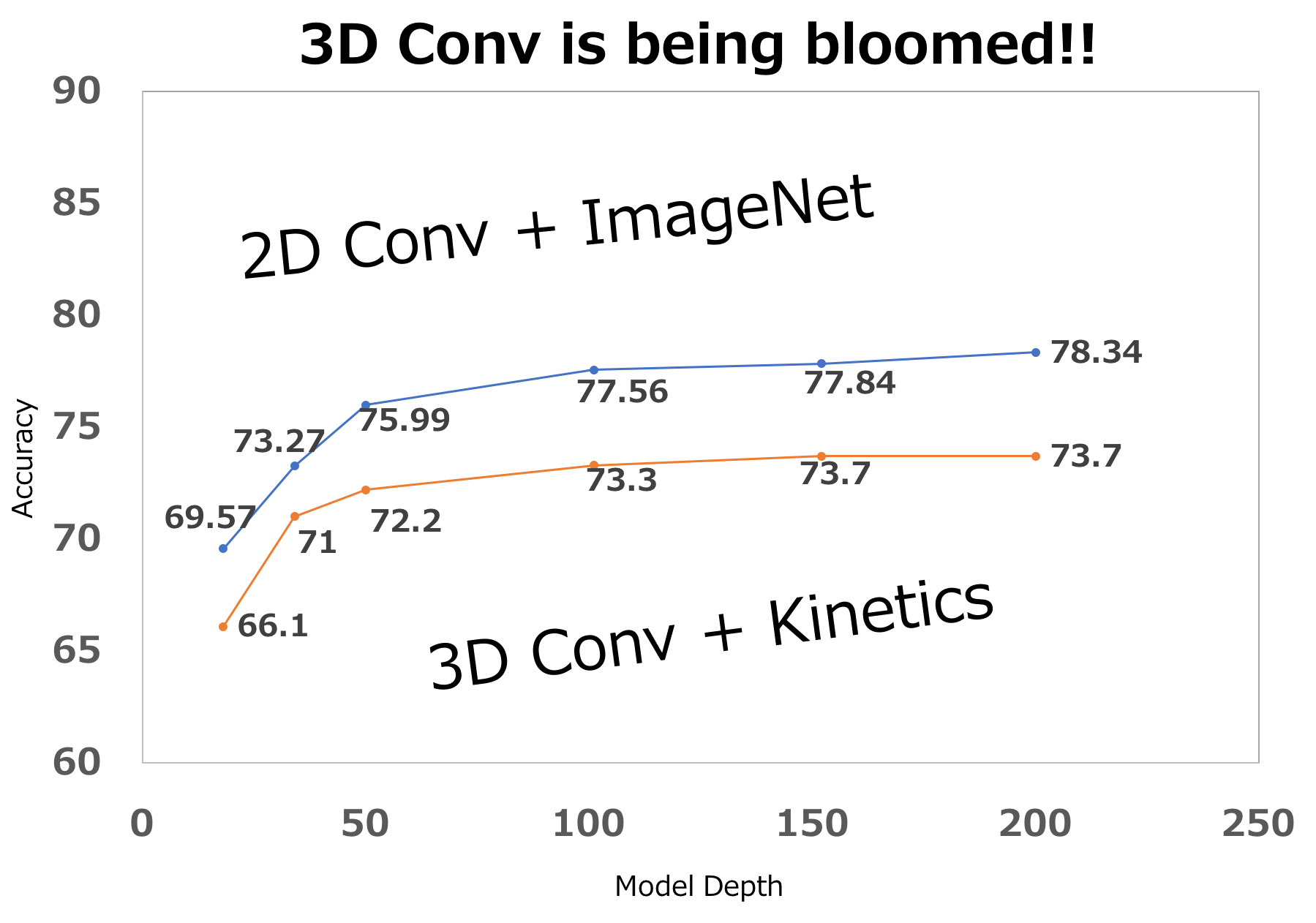
3D Conv is ready to be used various video applications!
The purpose of this study is to determine whether current video datasets have sufficient data for training very deep convolutional neural networks (CNNs) with spatio-temporal three-dimensional (3D) kernels. Recently, the performance levels of 3D CNNs in the field of action recognition have improved significantly. However, to date, conventional research has only explored relatively shallow 3D architectures. We examine the architectures of various 3D CNNs from relatively shallow to very deep ones on current video datasets. The Kinetics dataset has sufficient data for training of deep 3D CNNs, and enables training of up to 152 ResNets layers, interestingly similar to 2D ResNets on ImageNet. We believe that using deep 3D CNNs together with Kinetics will retrace the successful history of 2D CNNs and ImageNet.
-
投稿先
CVPR 2018, AIST Best Paper
-
メンバー
Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh (AIST)