
Profile
Bio.
1. Chief Senior Researcher, AIST/ 2. Academic Visitor, Visual Geometry Group (VGG), University of Oxford / 3. Visiting Associate Professor, Keio University / 4. Adjunct Associate Professor, Tokyo Denki University / 5. Research Advisor, SB Intuitions / 6. Principal Investigator, cvpaper.challenge / 7. Principal Investigator, LIMIT.Lab
He proposed 3D ResNets as a baseline spatiotemporal model, which became one of the top 0.5% most-cited papers at CVPR over a five-year period. He also introduced Formula-Driven Supervised Learning (FDSL), a synthetic pre-training method without real images and human labor, which earned an ACCV 2020 Best Paper Honorable Mention Award. He received the Fujiwara Prize in 2014 (valedictorian equivalent) from Keio University, participated in the ECCV 2016 Workshop “Brave New Idea,” and won the AIST Best Paper Award in 2019 and 2022, was also a BMVC 2023 Best Industry Paper Finalist. He has served as primary organizer of the LIMIT Workshops at ICCV 2023, CVPR 2024, and ICCV 2025, as Area Chair for CVPR 2024 and 2025, and will serve as an IEEE TPAMI Associate Editor beginning in 2025. His work has been featured in MIT Technology Review.
-
Latest Professional Experience
Visiting Researcher, Visual Geometry Group, University of Oxford (Oxford VGG)
(September, 2024 - ) -
Latest Education
Ph.D. in Engineering, Keio University
(April 2011 - March 2014)
What’s new?
-
Jun 09, 2025
We’ve established LIMIT.Lab [Link] a collaboration hub for building multimodal AI models under limited resources, covering images, videos, 3D, and text, when any resource (e.g., compute, data, or labels) is constrained.
-
Mar 06, 2025
-
Dec 21, 2024
Our paper (Audio FDSL) has been accepted to ICASSP 2025.
-
Sep 27, 2024
Two papers (Weakly Supervised Segmentation, Real-world Super Resolution) have been accepted to ACCV 2024.
-
Jul 01, 2024
Three papers (Super Resolution, Multimodal & Limited Pre-training) have been accepted to ECCV 2024.
Projects
-

LIMIT.Lab
Building multimodal AI foundation models with very limited resources!
-

cvpaper.challenge
We are finding a collaborator to read/write a sophisticated paper!
-

Pre-training without Natural Images / Formula-driven Supervised Learning (FDSL)
We would like to replace Supervised/Self-supervised Learning!
-
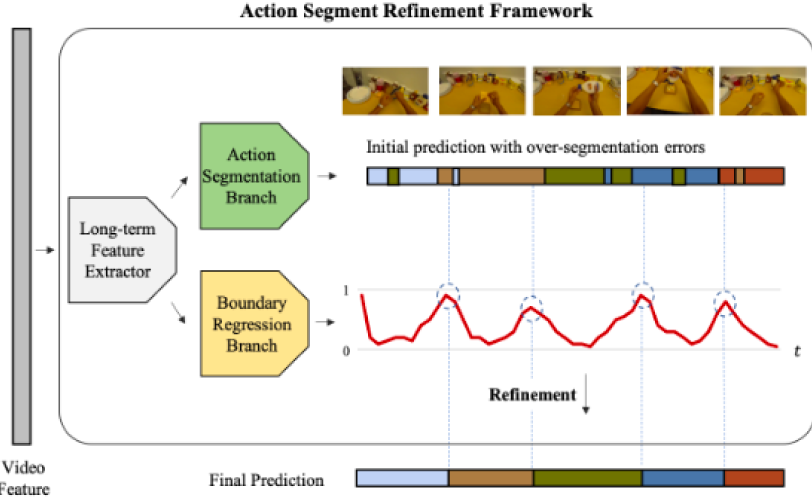
Alleviating Over-segmentation Errors by Detecting Action Boundaries
Detecting action boundary significantly improves segmentation performance.
-
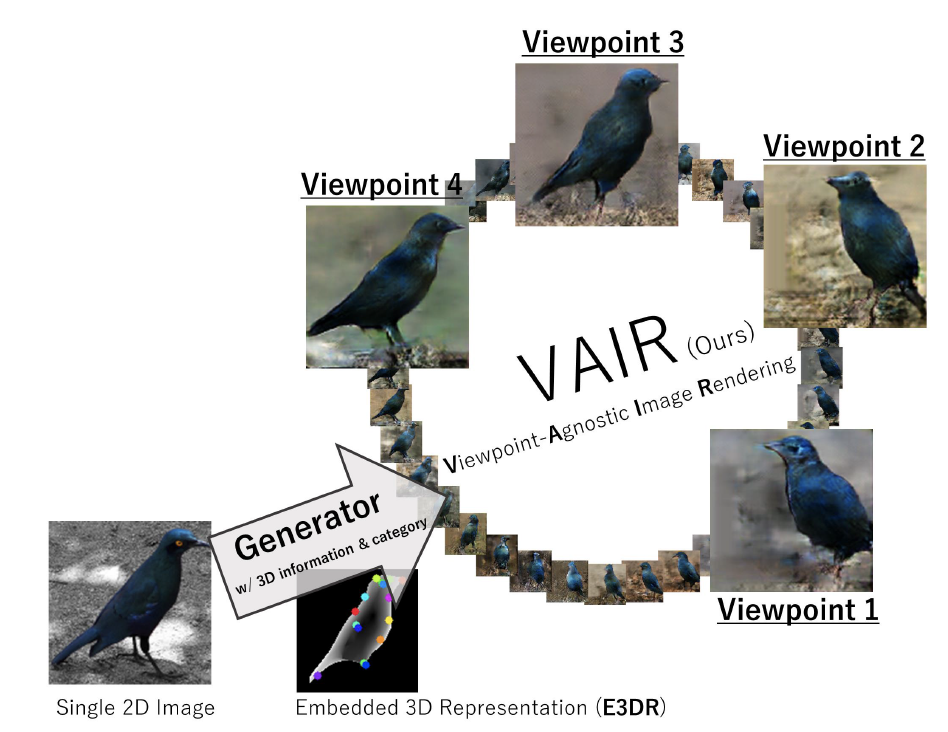
View-agnostic Image Rendering
We generate novel-view images.
-

Scene Change Captioning
We can describe a change area in a real environment.
-

Weakly Supervised Person Dataset (WSPD)
Our weak-supervision surpassed a supervised pre-training.
-

Neural Joking Machine: Humorous image captioning
Now we are joking!
-
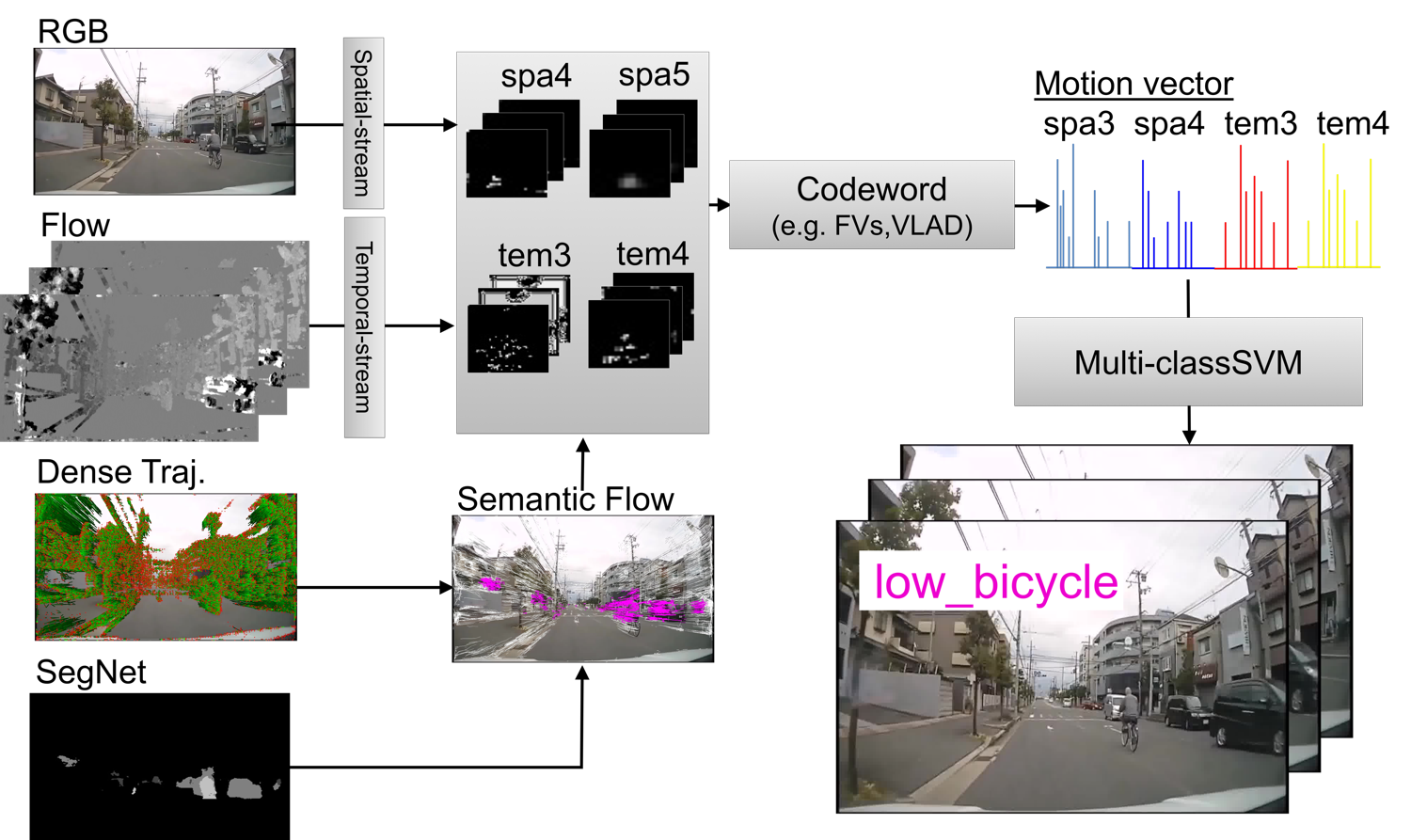
Drive Video Analysis for the Detection of Traffic Near-Miss Incidents
We have collected large-scale traffic near-miss incident database!
-
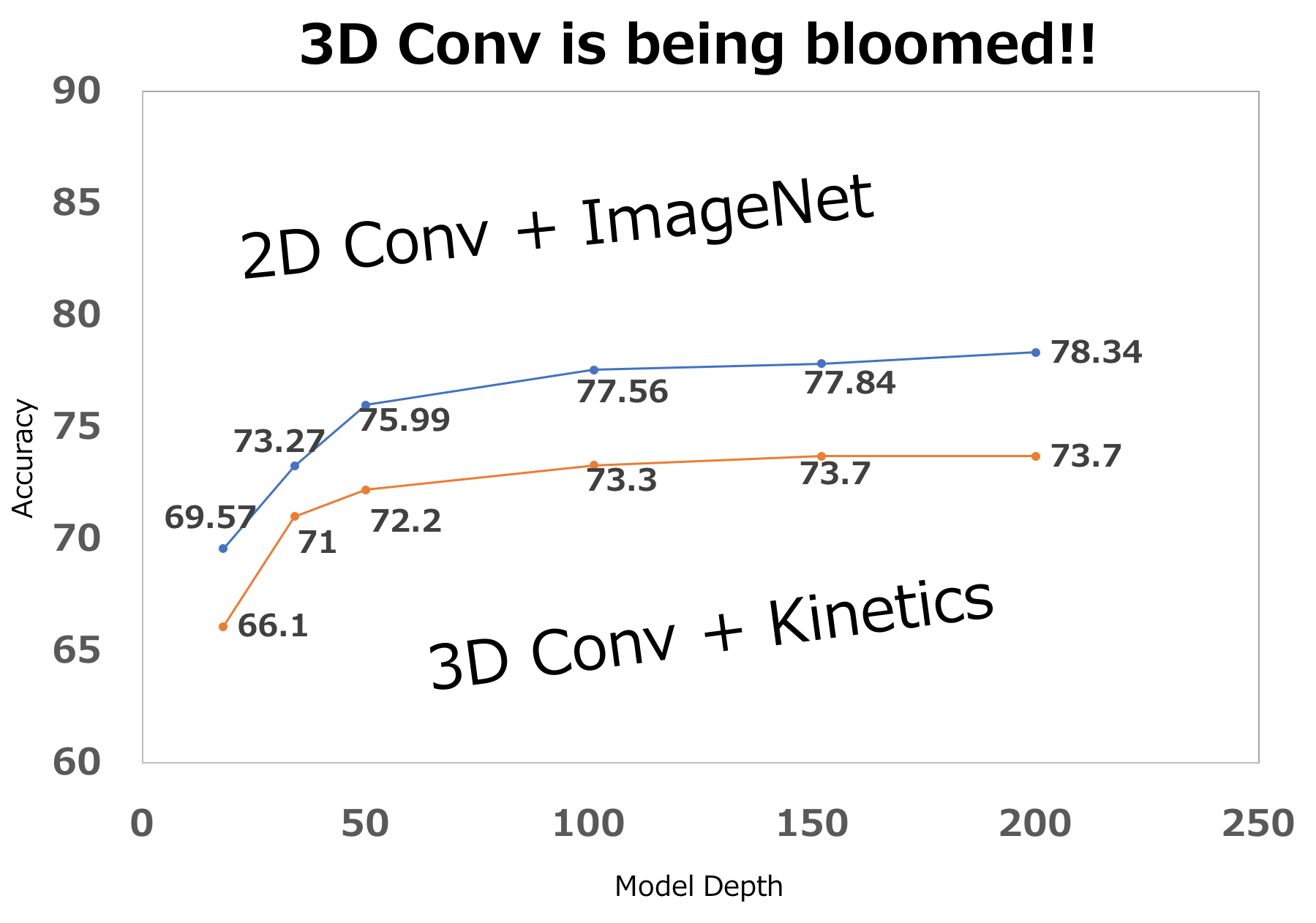
Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?
3D Conv is ready to be used various video applications!
Selected Papers
-
Selected Papers Top-Rank
Hirokatsu Kataoka, Ryo Hayamizu, Ryosuke Yamada, Kodai Nakashima, Sora Takashima, Xinyu Zhang, Edgar Josafat Martinez-Noriega, Nakamasa Inoue, Rio Yokota, “Replacing Labeled Real-Image Datasets with Auto-Generated Contours”, IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), 2022.(Acceptance rate: 25.3%; 1st place in Computer Vision at Google Scholar Metrics)
-
Selected Papers Top-Rank
Ryosuke Yamada*, Hirokatsu Kataoka*, Naoya Chiba, Yukiyasu Domae Tetsuya Ogata, “Point Cloud Pre-training with Natural 3D Structures”, IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), 2022.(Acceptance rate: 25.3%; 1st place in Computer Vision at Google Scholar Metrics; * indicates equal contribution)
-
Selected Papers Top-Rank
Hirokatsu Kataoka, Kazushige Okayasu, Asato Matsumoto, Eisuke Yamagata, Ryosuke Yamada, Nakamasa Inoue, Akio Nakamura, Yutaka Satoh, “Pre-training without Natural Images”, International Journal of Computer Vision (IJCV), 2022. (IF: 7.410)
-
Selected Papers Top-Rank
Kodai Nakashima, Hirokatsu Kataoka, Asato Matsumoto, Kenji Iwata, Nakamasa Inoue, Yutaka Satoh, “Can Vision Transformers Learn without Natural Images?,” AAAI Conference on Artificial Intelligence (AAAI), 2022.
-
Selected Papers Top-Rank
Hirokatsu Kataoka, Kazushige Okayasu, Asato Matsumoto, Eisuke Yamagata, Ryosuke Yamada, Nakamasa Inoue, Akio Nakamura, Yutaka Satoh, “Pre-training without Natural Images”, Asian Conference on Computer Vision (ACCV), 2020. (Best Paper Honorable Mention Award; Oral Presentation; 3 Strong Accepts)
Research Team
21 Total-
Kohei Torimi / 鳥見晃平
-
Yanjun Sun
( w/ Yue Qiu ) -
Go Ohtani / 大谷 豪
-
Yuto Matsuo / 松尾雄斗
( w/ Rintaro Yanagi ) -
Noritake Kodama / 児玉憲武
( w/ Rintaro Yanagi ) -
Erika Mori / 森 江梨花
( w/ Yue Qiu ) -
Daichi Otsuka / 大塚 大地
( w/ AL Lab )
-
Okubo Ren / 大久保蓮
( w/ Rintaro Yanagi ) -
Yuto Shibata / 柴田 優斗
( w/ Rintaro Yanagi ) -
Shogo Iwakata / 岩片 彰吾
( w/ Yue Qiu ) -
Fumiya Uchiyama / 内山 史也
( w/ Rintaro Yanagi )
-
Guoqing Hao / ハオ グオチン
( w/ Kensho Hara ) -
Takumi Fukuzawa / 福沢 匠
( w/ Kensho Hara )