
プロフィール
自己紹介
1. 産業技術総合研究所 上級主任研究員 / 2. オックスフォード大学 Visual Geometry Group (VGG) 学術訪問員 / 3. 慶應義塾大学 訪問准教授 / 4. 東京電機大学 客員准教授 / 5. SB Intuitions 研究アドバイザ / 6. cvpaper.challenge 主宰 / 7. LIMIT.Lab 主宰.
2026年現在 “LIMIT” および “VGI” という二つのPhilosophyを基盤として研究テーマの構築に取り組んでいる.LIMITでは,限定資源下におけるAI基盤モデル構築を主眼として研究を進めている(LIMIT.Lab 参照).また,AGI時代の到来を見据え,純粋に視覚機能の高度化を目指す Visual General Intelligence(VGI)というPhilosophyに基づく研究を積極的に推進している(CVPR 2026 VGI Workshop 参照)。
時空間モデルのベースラインである3D ResNetを提案し5年間のCVPRで最も引用された上位0.5%の論文として掲載.実画像を用いない画像認識AIの事前学習法である数式ドリブン教師あり学習 (Formula-Driven Supervised Learning; FDSL)を提案して2020年 ACCV 2020 Best Paper Honorable Mention Award受賞.その他,2011/2020年ViEW小田原賞,2014年藤原賞(慶應義塾大学理工学研究科 首席相当),2016年ECCV Workshop Brave New Idea,2019/2022年度産総研論文賞,BMVC 2023 Best Industry Paper Finalist,ICCV 2023, CVPR 2024, ICCV 2025 LIMIT Workshop Primary Organizer,CVPR 2024/2025 Area Chair,2025年よりTPAMI Associate Editor.研究はMIT Technology Reviewや日経ロボティクスなどのメディアにて掲載.
-
現職
オックスフォード大学 Visual Geometry Group(Oxford VGG)訪問研究員
(2024年9月 - ) -
最終学歴
慶應義塾大学大学院 理工学研究科 博士(工学)
(2011年4月 - 2014年3月)
新着情報
-
2025年12月22日
-
2025年11月26日
BMVC 2025 Workshop のトークスライドを公開しました [Link]
-
2025年9月18日
Domain Unlearning 論文が NeurIPS 2025 に採択されました
-
2025年7月17日
Google Zurich / ETH Zurich のトークスライドを公開しました [Link]
-
2025年7月8日
2本の論文(AnimalClue, AgroBench)がICCV 2025に採択されました
プロジェクト
-

LIMIT.Lab
Building multimodal AI foundation models with very limited resources!
-

cvpaper.challenge
We are finding a collaborator to read/write a sophisticated paper!
-

Pre-training without Natural Images / Formula-driven Supervised Learning (FDSL)
We would like to replace Supervised/Self-supervised Learning!
-
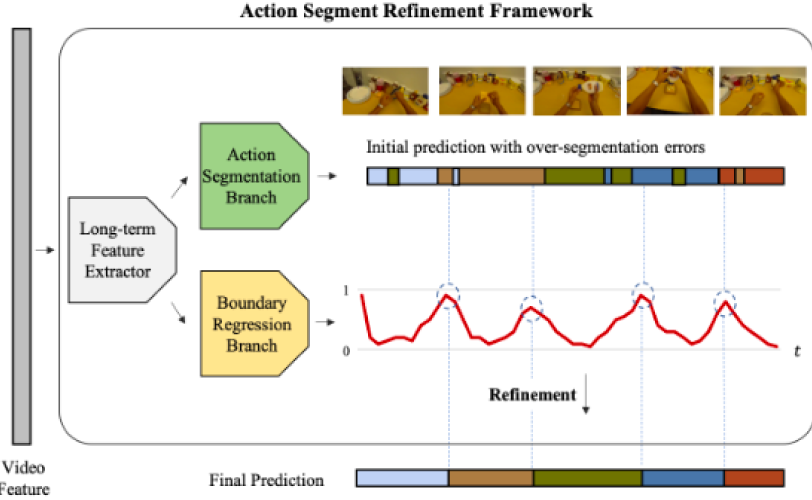
Alleviating Over-segmentation Errors by Detecting Action Boundaries
Detecting action boundary significantly improves segmentation performance.
-
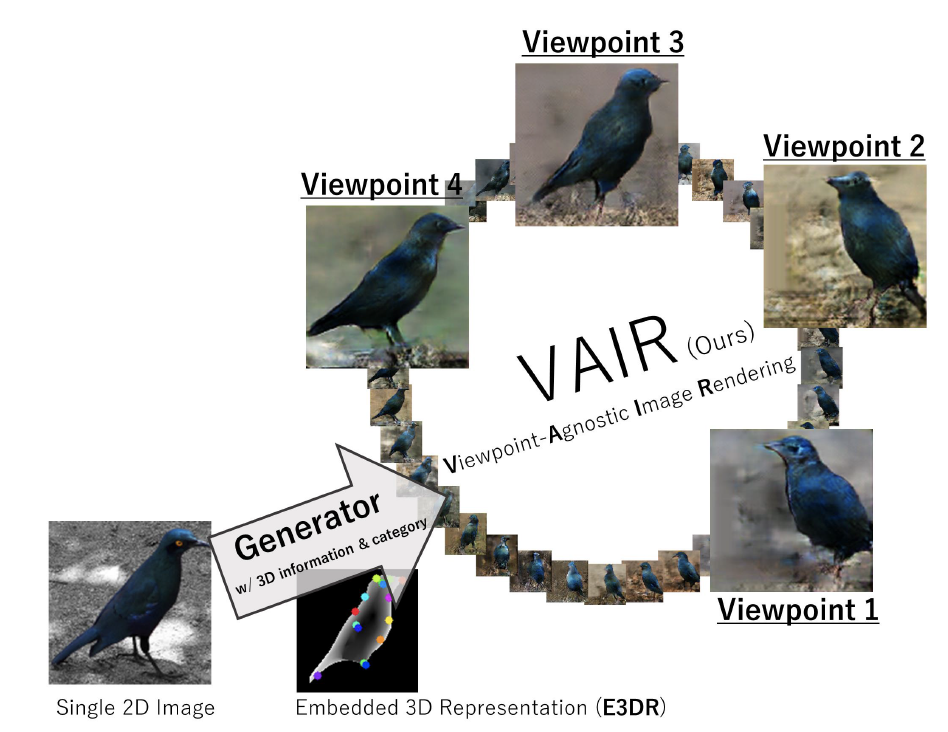
View-agnostic Image Rendering
We generate novel-view images.
-

Scene Change Captioning
We can describe a change area in a real environment.
-
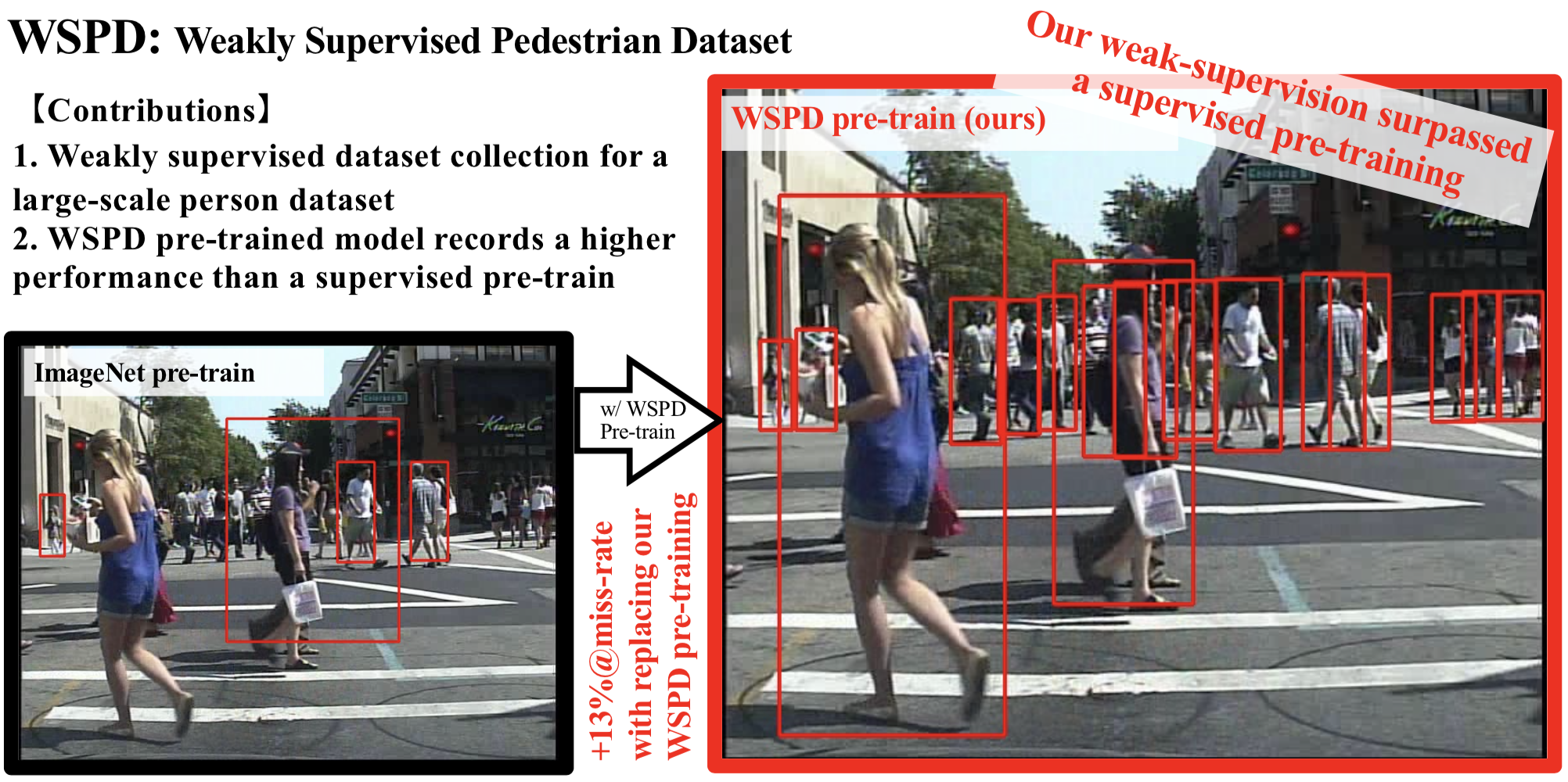
Weakly Supervised Person Dataset (WSPD)
Our weak-supervision surpassed a supervised pre-training.
-

Neural Joking Machine: Humorous image captioning
Now we are joking!
-
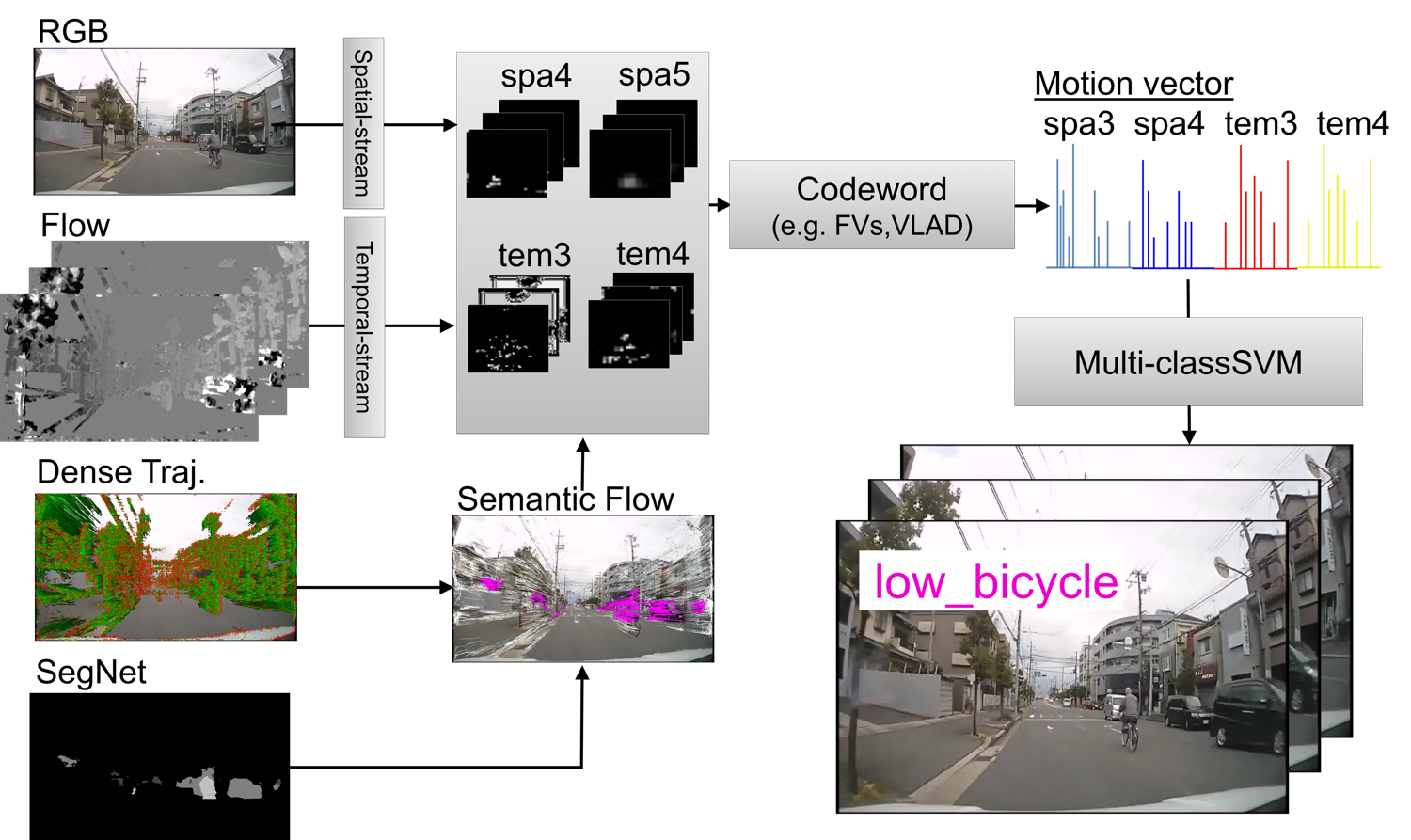
Drive Video Analysis for the Detection of Traffic Near-Miss Incidents
We have collected large-scale traffic near-miss incident database!
-
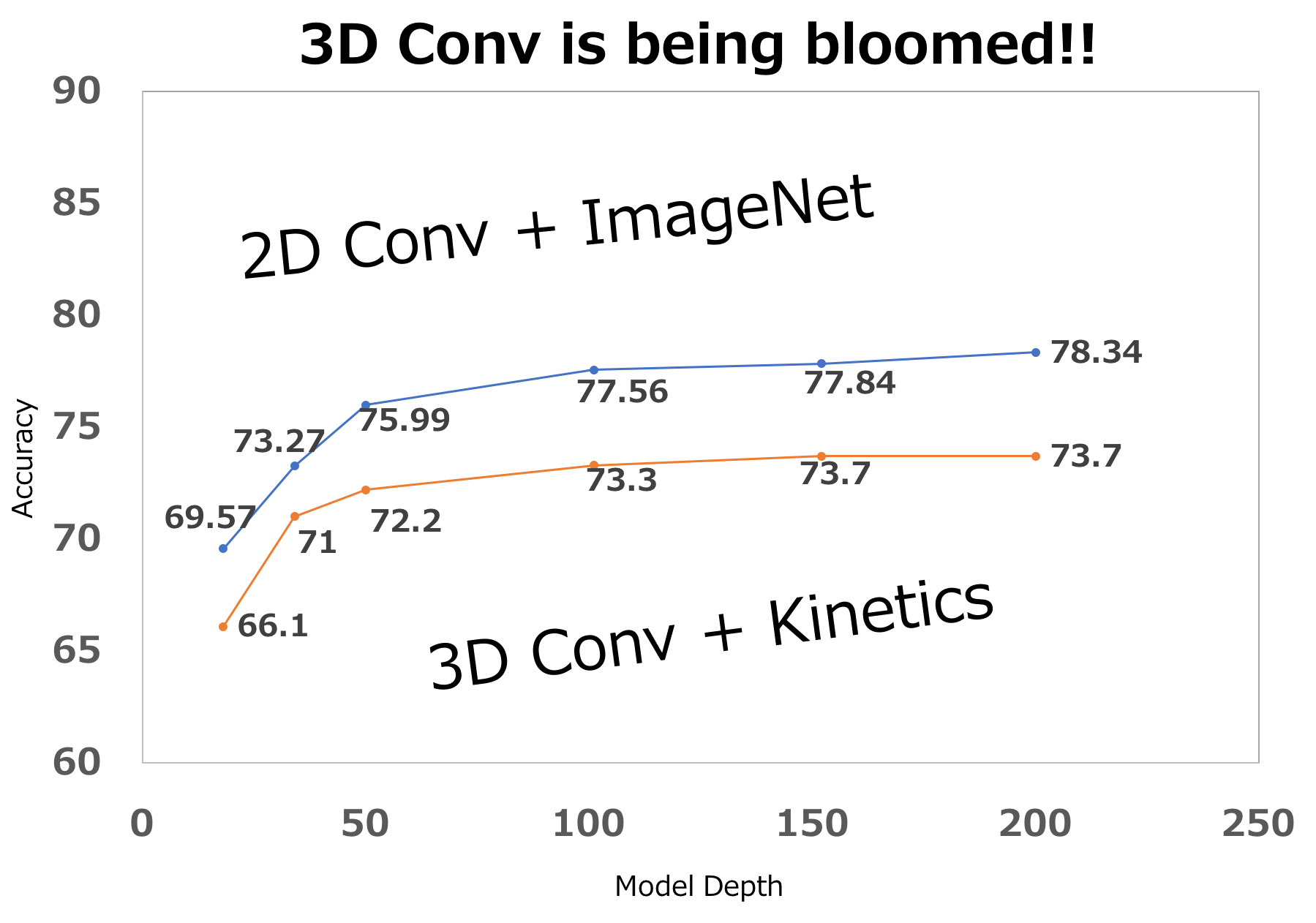
Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?
3D Conv is ready to be used various video applications!
主な論文
-
Selected Papers Top-Rank
Hirokatsu Kataoka, Ryo Hayamizu, Ryosuke Yamada, Kodai Nakashima, Sora Takashima, Xinyu Zhang, Edgar Josafat Martinez-Noriega, Nakamasa Inoue, Rio Yokota, “Replacing Labeled Real-Image Datasets with Auto-Generated Contours”, IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), 2022.(Acceptance rate: 25.3%; 1st place in Computer Vision at Google Scholar Metrics)
-
Selected Papers Top-Rank
Ryosuke Yamada*, Hirokatsu Kataoka*, Naoya Chiba, Yukiyasu Domae Tetsuya Ogata, “Point Cloud Pre-training with Natural 3D Structures”, IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), 2022.(Acceptance rate: 25.3%; 1st place in Computer Vision at Google Scholar Metrics; * indicates equal contribution)
-
Selected Papers Top-Rank
Hirokatsu Kataoka, Kazushige Okayasu, Asato Matsumoto, Eisuke Yamagata, Ryosuke Yamada, Nakamasa Inoue, Akio Nakamura, Yutaka Satoh, “Pre-training without Natural Images”, International Journal of Computer Vision (IJCV), 2022. (IF: 7.410)
-
Selected Papers Top-Rank
Kodai Nakashima, Hirokatsu Kataoka, Asato Matsumoto, Kenji Iwata, Nakamasa Inoue, Yutaka Satoh, “Can Vision Transformers Learn without Natural Images?,” AAAI Conference on Artificial Intelligence (AAAI), 2022.
-
Selected Papers Top-Rank
Hirokatsu Kataoka, Kazushige Okayasu, Asato Matsumoto, Eisuke Yamagata, Ryosuke Yamada, Nakamasa Inoue, Akio Nakamura, Yutaka Satoh, “Pre-training without Natural Images”, Asian Conference on Computer Vision (ACCV), 2020. (Best Paper Honorable Mention Award; Oral Presentation; 3 Strong Accepts)
研究チーム
合計25 名-
Qiu Yue(産総研 主任研究員) / Qiu Yue
( w/ Yutaka Satoh ) -
ハオ グオチン(青山学院大学 助教) / Guoqing Hao
( w/ 原健翔 ) -
大塚 大地(産総研 研究員) / Daichi Otsuka
( w/ ALラボ )
-
Yanjun Sun(SB Intuitions 研究員)
( w/ Yue Qiu )
-
鳥見晃平 / Kohei Torimi
-
大谷 豪 / Go Ohtani
-
金子 知紘 / Chihiro Kaneko
( w/ Daichi Otsuka ) -
川村 政貴 / Masaki Kawamura
( w/ Rintaro Yanagi ) -
松尾雄斗 / Yuto Matsuo
( w/ Rintaro Yanagi ) -
Noritake Kodama / 児玉憲武
( w/ Rintaro Yanagi )
-
西澤大樹 / Hiroki Nishizawa
( w/ Yoshihiro Fukuhara ) -
大久保蓮 / Okubo Ren
( w/ Rintaro Yanagi ) -
岩片 彰吾 / Shogo Iwakata
( w/ Qiu Yue ) -
内山 史也 / Fumiya Uchiyama
( w/ Rintaro Yanagi )